
Domain-Independent Vocabularies – K Dictionaries
What are they and why do we need them?
Domain-independent vocabularies in Lynx provide a common catalogue of word meanings which allow to traverse semantically annotated documents from different domains. They also serve as support for NLP tasks such as word sense disambiguation (WSD), question answering (QA), and cross-lingual search, and help to retrieve synonyms and translations, among other lexical data.
In Lynx, these vocabularies come in the form of multilingual lexicographic resources by the consortium partner K Dictionaries (KD), and they comprise, specifically, lexical data for Dutch, English, German and Spanish.
How is this data integrated into the LKG?
For these lexical resources to be easily integrated into the Legal Knowledge Graph (LKG), we rely on the semantic representation of the data as Linked Data (LD). To this end, the data needs to be first converted to the Resource Description Framework (RDF) format and semantically annotated through the use of ontologies. This serves to ensure both syntactic as well as semantic interoperability of the resulting datasets, accessible at the end of this process via a REST API.
The transformation process: from XML to RDF
The following figure illustrates the entire conversion process:
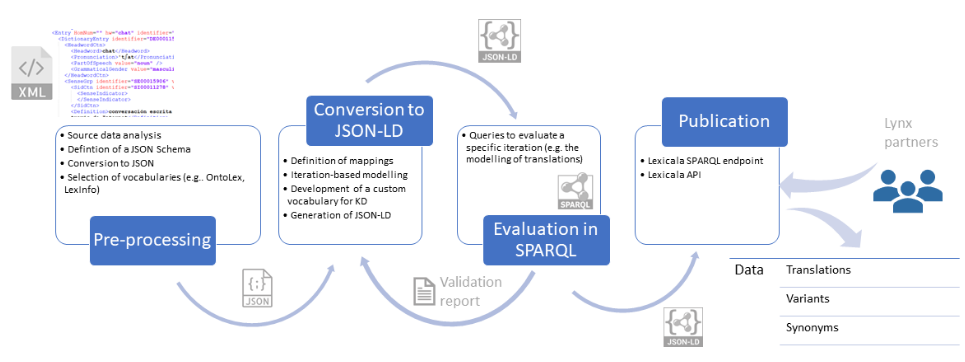
Source data analysis
The source data is based on KD’s multilingual Global series, implementing the model on each individual entry and relying on pre-existing relations in KD resources to further link information across languages. The data is originally in XML, which is then converted into JSON format. Each XML element of an entry is mapped to a corresponding JSON type (including strings, arrays and objects) and each entry is represented by a single JSON object containing the entry components within.
A standard entry in the data consists of the headword, part of speech, grammatical information (such as sub-categorization, number or gender) and other semantic and syntactic information. Entries can be either monosemous (i.e. consisting of a single sense) or polysemous (i.e. divided into multiple senses) and each sense contains a definition and/or some indicator of the specific meaning. Such information can include register, subject field or sentiment, as well as synonyms and antonyms, example phrases, multiword expressions and translation equivalents in other languages.
These components are represented in a structured JSON format and governed by a schema to arrange the information in place and check that the relations between the different nested objects are correct, making sure that no ill-fitted relationship occurs in the data, thus enabling a stable and reliable basis for RDF implementation and conversion.
Model definition and conversion to JSON-LD
The semantic representation of the data as LD is based on the OntoLex-lemon model and its lexicog and vartrans modules. The OntoLex-lemon model is the de facto standard to represent lexical resources as LD. It consists of an RDF model that, with a set of core classes (such as ontolex:LexicalEntry or ontolex:LexicalSense) and several modules, allows for the representation of a wide range of lexical descriptions including morphosyntactic properties, translations, and pragmatic information. This model is commonly used with other ontologies such as LexInfo, which serves as a linguistic category registry. For example, OntoLex-lemon enables describing in RDF a dictionary entry as a lexical entry, its module lexicog adds further description to encode how this entry is arranged in the specific resource it comes from (e.g. if it is a headword or not), the vartrans module makes it possible to represent translations between this lexical entry and others, and LexInfo offers elements to specify its morphosyntactic features (part of speech, gender, number, etc.). A custom ontology for KD was also designed for those cases in which LexInfo did not provide a linguistic category equivalent to the original description in KD’s DTD.
Once the model was defined, the process of converting KD data into LD was carried out following an incremental approach, starting with the very basics of a single entry (headword, part of speech, senses, definitions) and proceeding with more complicated elements, including synonyms, compounds, examples of usage, translations, etc. Each iteration focused on the modelling of a specific type of linguistic information and implementing the modelling decisions in the pipeline to generate JSON-LD.
The details on the URI naming strategy adopted for the conversion, as well as the linking advantages it offers across dictionaries, is presented in detail in Lonke and Bosque-Gil (2020).
Evaluation
After generating the corresponding JSON-LD entries for each iteration, the resulting data was validated iteratively through SPARQL queries. A series of queries were defined, specifically targeted at evaluating how the representation of the linguistic information covered in that iteration was implemented in the pipeline and whether the model was followed accordingly. This incremental process has not only assured constant validation and error handling, but also allowed for an adaptation period, during which the process of writing queries for validation has shed more light on the model and methods of improvement. Taking into account the data requirements of the Lynx services and our initial experiments with the RDF data, we have been able to improve the queries and iteratively change the model so that the results optimally represent the users’ needs.
The details on the first modelling efforts with KD lexicographic data in OntoLex are elaborated on Bosque-Gil et al. (2016), while the application of the lexicog module and the iterative evaluation are presented in detail in Bosque-Gil et al (2019).
Publication and exploitation
The resulting dataset provides a wide array of lexicographic components represented as RDF with OntoLex-Lemon, LexInfo and KD custom ontology, including the headword, part of speech, inflections, grammatical information, examples of usage, multiword expressions, synonyms and antonyms, and translation equivalents accessible via the SPARQL endpoint to the Lynx partners. The entries are linked across KD’s multilingual Global series through translation relations (across source and target languages), and monolingual sense relations (antonomy, synonymy). This leads to the emergence of a graph of lexical data, illustrated here in the visual rendering of the English entry bow (noun) and its homographs:

Some example queries over the graph of lexical data are provided and documented in Lonke and Bosque-Gil (2020).
K Dictionaries multilingual data is being exploited by several Lynx services (https://lynx-project.eu/doc/api/). It is being used by the Search services to perform query expansion through a series of SPARQL queries which, given a lemma, return the lemmas of the synonyms (non-inflected forms) and the inflections (if available). It is also being used in the creation of ad-hoc terminologies to provide synonyms and translations of relevant terms, and also in the disambiguation process of data retrieved from the Linguistic Linked Open Data cloud.
References
Bosque-Gil, J., Gracia, J., Montiel-Ponsoda, E., and Aguado-de-Cea, G. (2016). Modelling multilingual lexicographic resources for the Web of Data: The K Dictionaries case. In GLOBALEX 2016 Lexicographic Resources for Human Language Technology Workshop Programme (pp. 65-72). https://ufal.mff.cuni.cz/~kolarova/2016/docs/LREC2016Workshop-GLOBALEX_Proceedings-v2.pdf#page=71
Bosque-Gil, J., Lonke, D., Gracia, J., & Kernerman, I. (2019). Validating the OntoLex-lemon lexicography module with K Dictionaries’ multilingual data. In Electronic lexicography in the 21st century. Proceedings of the eLex 2019 conference (pp. 726-746). https://elex.link/elex2019/wp-content/uploads/2019/09/eLex_2019_41.pdf
Lonke, D., and Bosque-Gil, J. (2020) Applying the OntoLex-lemon lexicography module to K Dictionaries’ multilingual data. Kernerman Dictionary News, 28. https://kln.lexicala.com/kln28/lonke-bosque-gil-ontolex-lemon-lexicog/